摘要:本文学习了索引的数据结构和相关的概念,以及如何使用工具分析和优化。
环境
CentOS Linux release 7.6.1810
MySQL 5.7.40
1 数据结构
1.1 分类
索引是在存储引擎层中实现的,而不是在服务器层实现的。所以每种存储引擎的索引都不一定完全相同,也不是所有的存储引擎都支持所有的索引类型的。
常见的索引有四种结构类型:
- B树索引:最常见的索引类型,大部分索引都支持该类型的索引。
- Hash索引:基于Hash表实现,只有Memory引擎支持,使用场景简单。
- R树索引(空间索引):空间索引是MyISAM引擎的一个特殊索引类型,主要用于地理空间数据类型,通常使用较少。
- FullText(全文索引):全文索引也是MyISAM的一个特殊索引类型,主要用于全文检索。InnoDB从5.6版本开始支持全文索引,但并不直接支持中文,需要使用插件辅助。
1.2 说明
1.2.1 B树
B树是为了磁盘或其它存储设备而设计的一种多叉平衡查找树。相对于二叉树,B树每个内结点有多个分支,所以是多叉树。
一颗m叉的B树特性如下:
- 树中每个节点最多有m个孩子节点,如果根节点不是叶子节点,则至少有2个孩子节点。
- 除根节点与叶子节点外,每个节点由n个key与n+1个point组成,其中n的取值在ceil(m/2)-1和m-1之间,ceil是一个取上限的函数。
- 节点的key包含索引的键值和键值所在行的数据,节点的point指向孩子节点,如果是叶子节点,其point指向null节点,并且所有的叶子节点都在同层。
- 当孩子节点的数量超过m-1时,中间节点会成为父节点,孩子节点分裂为左右两块孩子节点。
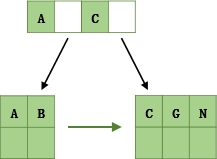
以一个3叉B树为例,当m为3时,n的取值在1和2之间,当key的个数大于2时,中间节点分裂到父节点,两边节点分裂。
插入ACGBNMQW的演变过程如下:
- 插入AC
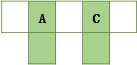
- 插入G,n>2,中间C向上分裂到新节点
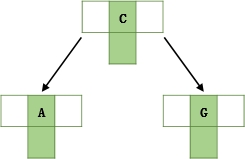
- 插入BN,不需要分裂
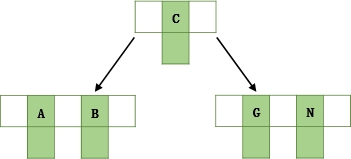
- 插入M,中间M向上分裂到父节点
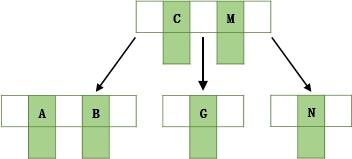
- 插入Q,不需要分裂
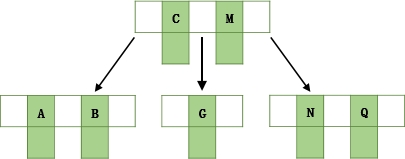
- 插入W,中间Q向上分裂到父节点,父节点中间M向上分裂到新节点
和二叉树相比,B树有如下优点::
- 查询效率更高。在相同的数据量情况下,B树查询数据的时间复杂度更低。
- 搜索速度更快。B树层级结构小,查询效率更高。
1.2.2 B+树
B+树是B树的一个变种,但也同样属于多叉平衡查找树。
一颗m叉的B+树特性如下:
- 树中每个节点最多有m个孩子。
- 如果根节点不是叶子节点,则至少有2个孩子。
- 除根节点与叶子节点外,每个节点由n个key与n个point组成,其中ceil(m/2)<=n<=m,ceil是一个取上限的函数。
- 叶子节点都在同一层,叶子节点没有point,叶子节点的key包含全部索引的键值和键值所在行的数据。
- 非叶子节点的point指向孩子节点,非叶子节点的key包含孩子节点中最大(或最小)的key。
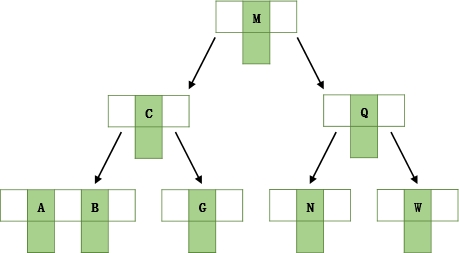
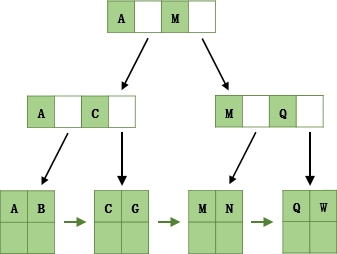
以一个3叉B+树为例,2<=n<=3,当key的个数大于3时,中间节点分裂到父节点,两边节点分裂。
插入ACGBNMQW的演变过程如下:
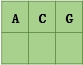
- 插入ACG
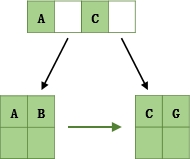
- 插入B,n>3,分裂
- 插入N,不需要分裂
- 插入M,分裂
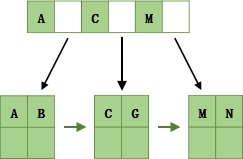
- 插入Q,不需要分裂
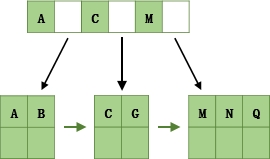
- 插入W,分裂
和B树相比,B+树有如下优点:
- 扫表能力更强。B树需要遍历整棵树,B+树只需要遍历所有叶子节点。
- 磁盘读写能力更强。在同样大小的情况下,B+树只有叶子节点保存数据,保存的关键字和数据更多。
- 查询性能稳定。B+树数据只保存在叶子节点,每次查询数据,查询IO次数一定是稳定的。
- 查询效率高。B树在遍历时如果命中直接返回,B+树需要遍历到叶子节点。
2 相关定义
2.1 聚簇索引
2.1.1 定义
索引中的键值顺序就是表中相应行的物理存储顺序。对于经常要搜索范围值的列特别有效,表中排序经常用到的列可以使用聚簇索引节省成本。
在聚簇索引中,叶子节点存储的是真实数据,不再有另外单独的数据页。
优点是查询速度快,一旦具有第一个索引值的数据行被找到,具有连续索引值的数据行也会紧随其后。
缺点是修改速度慢,为了保证数据行的顺序和索引的顺序一致,需要进行数据重排,不适用于频繁更新的列。
2.1.2 使用
如果定义了主键,InnoDB会将这个主键索引作为聚簇索引。
如果没有定义主键,InnoDB会将第一个非空唯一索引作为聚簇索引。
如果没有主键索引并且没有非空唯一索引,InnoDB会自动创建一个隐藏的名字为GEN_CLUST_INDEX的聚簇索引。
因此,每个InnoDB表都有且仅有一个聚簇索引。
2.2 非聚簇索引
2.2.1 定义
索引中的键值顺序与表中相应行的物理存储顺序无关。
在非聚簇索引中,叶子节点存储的是索引节点,有一个指向对应数据页上的真实数据的指针。
2.2.2 使用
所有不是聚簇索引的索引都叫非聚簇索引或者辅助索引。
在InnoDB存储引擎中,非聚簇索引的每条记录会包含对应的主键,InnoDB会使用这个主键来检索聚簇索引。
因此应该尽可能将主键缩短,否则辅助索引占用空间会更大。
2.2.3 回表查询
当要查询的列不属于主索引和辅助索引,并且在查询条件中使用了辅助索引而且没有使用主索引。
此时,如果要的到查询结果,首先根据查询条件搜索辅助索引,找到符合的叶子节点,因为辅助索引没有索引覆盖查询的列,通过叶子节点上的主键搜索主索引,从而得到查询结果。
这个过程就是回表查询。
3 索引下推
索引下推(Index Condition Pushdown)简称ICP,在5.6的版本中推出。
ICP主要用于优化使用非聚簇索引的查询语句,可以减少回表次数。对于使用聚簇索引的查询语句,因为不需要回表,所以ICP并没有起到提示性能的效果。
使用ICP可以减少存储引擎回表的次数,也可以减少服务器从存储引擎接收数据的次数:
在不使用ICP的情况下,存储引擎通过索引检索到数据,然后返回给服务器,服务器判断数据是否符合条件 。
在使用ICP的情况下,存储引擎通过索引判断数据是否符合条件,然后返回给服务器。
4 索引优化
4.1 创建规则
建议创建索引的场景:
- 主键自动建立唯一索引。
- 经常作为查询条件的列要建立索引。
- 经常作为排序的列要建立索引。
- 在聚合函数中使用的列需要建立索引。
- 查询中与其他表关联的字段,以及外键关系要建立索引。
- 高并发条件下倾向使用组合索引。
不建议创建索引的场景:
- 经常增删改的列不要建立索引。
- 有大量重复的列不建立索引。
- 表记录太少不要建立索引。只有当数据库里的记录超过了1000条、数据总量也超过了MySQL服务器上的内存总量时,使用索引才有意义。
4.2 利用索引
4.2.1 全词匹配
最推荐的方式是使用全词匹配,也就是使用等号去查询数据,即便字段没有按照组合索引的顺序查询,优化器也能自动进行顺序优化。
4.2.2 范围匹配
不太推荐使用范围匹配的方式查询数据,因为这种方式可能会导致索引失效。
凡是表示有多个查询条件的方式都可以看做范围匹配,有可能使用范围级别的索引,也有可能不使用索引,但都会导致组合索引后面的字段失效。
说明:
- 使用不等于号不会使用索引。
- 使用大于号和小于号会使用范围级别的索引。
- 使用大于等于号和小于等于号会根据实际查询数据判断,如果全盘扫描速度快则不使用索引。
- 使用IN和EXISTS会导致索引失效。
- 使用LIKE关键字时,如果不是通配符开头会用到范围级别的索引,否则通配符开头不会使用索引。
- 使用IS NULL和IS NOT NULL同样会导致索引失效。
- 使用OR也会导致索引失效。
4.2.3 最佳左前缀
主要针对组合索引的情况。
如果查询语句正确使用了索引中定义的第一个字段,那么查询语句才能用到索引,索引才会对查询语句有效。
只有当前一个字段用到了索引,后一个字段才有可能用到索引。换句话说,如果组合索引的中间字段没有用到索引,那么后面的字段也不可能用到索引。
4.2.4 精确查找
尽量使用哪些字段就查询哪些字段,避免使用通配符。
4.2.5 覆盖索引
覆盖索引指的是只要查询字段都在索引中,查询就会使用到索引,和查询条件无关。
覆盖索引的原理是查询字段在索引中就能查到记录,不需要再次查询主索引中的记录,避免了回表,从而提高了性能。
在查询语句中,如果使用了范围查询条件,可能会导致索引失效,此时可以通过优化查询字段实现覆盖索引,使索引生效。
4.2.6 小表驱动大表
判断小表和大表可以根据MySQL优化器先加载哪个数据集,优先加载的被看做小表,相当于双层循环的外循环。
保证被驱动表上的条件字段已经被索引,换句话说,在大的数据集上优先建立索引。
说明:
- 连接查询使用JOIN时,优先加载ON后面连接条件等号左边的部分,所以将等号左边的部分看做小表,等号左边的小表驱动等号右边的大表,需要给右边的字段建立索引。
- 子查询使用IN时,优先加载子查询,所以将子查询看做小表,子查询驱动主查询,需要给主查询建立索引。
- 子查询使用EXISTS时,优先加载主查询,所以将主查询看做小表,主查询驱动子查询,需要给子查询建立索引。
4.2.7 避免操作
尽量避免在索引列上进行任何操作,包括但不限于计算、函数、类型转换,都会导致索引失效。
需要注意的是,误加和漏加单引号属于类型转换,也会导致索引失效。
4.2.8 排序功能
主要是针对排序操作。
索引的作用除了可以用来查找之外,还可以用来排序。
如果索引能用来排序则使用Index方式排序,如果索引不能用来排序则使用FileSort方式排序。
4.2.8.1 Index方式排序
尽量使用索引中的字段排序,并且保持索引中字段的顺序。
需要注意的是,排序是在查找之后,如果排序的字段在查找中出现过,即便顺序颠倒,也可以使用索引的排序功能。
4.2.8.2 FileSort方式排序
如果不能通过Index方式排序,则会使用FileSort方式排序。
FileSort方式有两种策略:
- 双路排序:第一次扫描磁盘读取行指针和要排序的字段,然后在缓冲区进行排序,第二次读取缓冲区排好序的列表,根据行指针重新扫描磁盘得到数据输出。
- 单路排序:扫描磁盘读取所有需要的列,然后在缓冲区进行排序,读取缓冲区排好序的列表输出。
在4.1之前使用双路排序,在4.1之后使用单路排序。
单路排序的效率更快一点,避免二次读取,但单路排序也存在问题。当取出的数据超出了缓冲区容量,就回导致每次只能读取缓冲区大小的数据进行排序,然后重复读取导致多次IO操作。
优化单路排序的思路:
- 增大sort_buffer_size参数:不管用哪种算法,提高这个参数都会提高效率,当然,要根据系统的能力去提高,因为这个参数是针对每个进程的。
- 增大max_length_for_sort_data参数:提高这个参数,会增加用改进算法的概率。但是如果设的太高,数据总容量超出sort_buffer_size的概率就增大。
4.2.9 分组功能
主要是针对分组操作。
分组的操作是在查找和排序之后,建议安装查找和排序的顺序进行分组。
WHERE优先于HAVING,能在WHERE中实现的筛选就不要放在HAVING中。
4.3 查询分析
4.3.1 准备数据
创建user表并插入数据:
1 | CREATE TABLE `user` ( |
创建bill表并插入数据:
1 | CREATE TABLE `bill` ( |
创建bill_detail表并插入数据:
1 | CREATE TABLE `bill_detail` ( |
4.3.2 优化器
MySQL中有专门负责优化查询语句的优化器,主要功能是通过计算分析系统中收集到的统计信息,为客户端请求的SQL提供最优的执行计划。
但优化器认为的最优的数据检索方式,不一定是DBA认为的最优的数据检索方式,这部分最耗费时间。
4.3.3 分析工具
使用explain可以查看优化器将如何执行SQL语句。
示例:
1 | mysql> explain select * from user; |
4.3.4 字段说明
4.3.4.1 id
查询的序列号,表示查询中操作表的顺序,一行对应一个查询语句。
结果包含四种情况:
- 相同
执行顺序从上到下:sql 1
2
3
4
5
6
7
8
9
10mysql> explain select b.* from bill b, bill_detail bd where b.id = bd.bill_id;
+----+-------------+-------+------------+-------+---------------+-------------+---------+------+------+----------+----------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+-------------+---------+------+------+----------+----------------------------------------------------+
| 1 | SIMPLE | bd | NULL | index | idx_bill_id | idx_bill_id | 5 | NULL | 4 | 100.00 | Using index |
| 1 | SIMPLE | b | NULL | ALL | PRIMARY | NULL | NULL | NULL | 3 | 50.00 | Using where; Using join buffer (Block Nested Loop) |
+----+-------------+-------+------------+-------+---------------+-------------+---------+------+------+----------+----------------------------------------------------+
2 rows in set (0.02 sec)
mysql> - 不同
执行顺序由大到小,子查询递增:sql 1
2
3
4
5
6
7
8
9
10mysql> explain select b.* from bill b where b.user_id = (select u.id from user u where u.username = '张三');
+----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+-------------+
| 1 | PRIMARY | b | NULL | ref | idx_user_id | idx_user_id | 5 | const | 2 | 100.00 | Using where |
| 2 | SUBQUERY | u | NULL | ALL | NULL | NULL | NULL | NULL | 2 | 50.00 | Using where |
+----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+-------------+
2 rows in set (0.02 sec)
mysql> - 同时存在
先按照从大到小的顺序排列,然后按照从上到下的顺序执行:sql 1
2
3
4
5
6
7
8
9
10
11mysql> explain select b.* from bill b, bill_detail bd where b.id = bd.bill_id and b.user_id = (select u.id from user u where u.username = '张三');
+----+-------------+-------+------------+------+---------------------+-------------+---------+-----------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------------+-------------+---------+-----------+------+----------+-------------+
| 1 | PRIMARY | b | NULL | ref | PRIMARY,idx_user_id | idx_user_id | 5 | const | 2 | 100.00 | Using where |
| 1 | PRIMARY | bd | NULL | ref | idx_bill_id | idx_bill_id | 5 | test.b.id | 1 | 100.00 | Using index |
| 2 | SUBQUERY | u | NULL | ALL | NULL | NULL | NULL | NULL | 2 | 50.00 | Using where |
+----+-------------+-------+------------+------+---------------------+-------------+---------+-----------+------+----------+-------------+
3 rows in set (0.02 sec)
mysql> - NULL
最后执行NULL查询:sql 1
2
3
4
5
6
7
8
9
10
11mysql> explain select u.* from user u where u.username = '张三' union select u.* from user u where u.username = '李四';
+------+--------------+------------+------------+------+---------------+------+---------+------+------+----------+-----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+------+--------------+------------+------------+------+---------------+------+---------+------+------+----------+-----------------+
| 1 | PRIMARY | u | NULL | ALL | NULL | NULL | NULL | NULL | 2 | 50.00 | Using where |
| 2 | UNION | u | NULL | ALL | NULL | NULL | NULL | NULL | 2 | 50.00 | Using where |
| NULL | UNION RESULT | <union1,2> | NULL | ALL | NULL | NULL | NULL | NULL | NULL | NULL | Using temporary |
+------+--------------+------------+------------+------+---------------+------+---------+------+------+----------+-----------------+
3 rows in set (0.02 sec)
mysql>
4.3.4.2 select_type
查询的类型,主要是用于区别普通查询、联合查询、子查询等复杂查询。
常见类型:
- SIMPLE
表示简单查询,当前查询中不包含子查询和UNION查询: - PRIMARY
表示查询中包含子查询,当前查询是最外层查询。 - SUBQUERY
表示在SELECT语句或WHERE语句中包含子查询。 - UNION
表示被UNION的查询,即处于UNION之后的查询。 - UNION RESULT
表示将UNION的结果作为表进行查询。
特殊类型:
- DEPENDENT SUBQUERY
表示在子查询内部依赖外部进行查询:sql 1
2
3
4
5
6
7
8
9
10mysql> explain select b.* from bill b where exists (select u.id from user u where b.user_id = u.id);
+----+--------------------+-------+------------+--------+---------------+---------+---------+----------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+--------------------+-------+------------+--------+---------------+---------+---------+----------------+------+----------+-------------+
| 1 | PRIMARY | b | NULL | ALL | NULL | NULL | NULL | NULL | 3 | 100.00 | Using where |
| 2 | DEPENDENT SUBQUERY | u | NULL | eq_ref | PRIMARY | PRIMARY | 4 | test.b.user_id | 1 | 100.00 | Using index |
+----+--------------------+-------+------------+--------+---------------+---------+---------+----------------+------+----------+-------------+
2 rows in set (0.04 sec)
mysql> - DEPENDENT UNION
表示在UNION查询内部依赖外部进行查询:sql 1
2
3
4
5
6
7
8
9
10
11
12mysql> explain select b.* from bill b where exists (select u.id from user u where b.user_id = u.id union select u.id from user u where b.user_id = u.id);
+------+--------------------+------------+------------+--------+---------------+---------+---------+----------------+------+----------+-----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+------+--------------------+------------+------------+--------+---------------+---------+---------+----------------+------+----------+-----------------+
| 1 | PRIMARY | b | NULL | ALL | NULL | NULL | NULL | NULL | 3 | 100.00 | Using where |
| 2 | DEPENDENT SUBQUERY | u | NULL | eq_ref | PRIMARY | PRIMARY | 4 | test.b.user_id | 1 | 100.00 | Using index |
| 3 | DEPENDENT UNION | u | NULL | eq_ref | PRIMARY | PRIMARY | 4 | test.b.user_id | 1 | 100.00 | Using index |
| NULL | UNION RESULT | <union2,3> | NULL | ALL | NULL | NULL | NULL | NULL | NULL | NULL | Using temporary |
+------+--------------------+------------+------------+--------+---------------+---------+---------+----------------+------+----------+-----------------+
4 rows in set (0.04 sec)
mysql> - DERIVED
表示在FROM语句中包含子查询,递归执行这些子查询并将结果放在临时表里:sql 1
2
3
4
5
6
7
8
9
10mysql> explain select * from (select b.user_id, count(1) from bill b group by b.user_id) as b;
+----+-------------+------------+------------+-------+---------------+-------------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+-------+---------------+-------------+---------+------+------+----------+-------------+
| 1 | PRIMARY | <derived2> | NULL | ALL | NULL | NULL | NULL | NULL | 3 | 100.00 | NULL |
| 2 | DERIVED | b | NULL | index | idx_user_id | idx_user_id | 5 | NULL | 3 | 100.00 | Using index |
+----+-------------+------------+------------+-------+---------------+-------------+---------+------+------+----------+-------------+
2 rows in set (0.04 sec)
mysql>
4.3.4.3 table
表示查询用到的表是哪个。
4.3.4.4 partitions
匹配的分区信息,表示存在哪个分区,使用NULL表示没有分区。
4.3.4.5 type
查询使用的访问类型,是比较重要的一个指标。
结果从最优到最差的分别为:systen,const,eq_ref,ref,ref_or_null,index_merge,unique_subquery,index_subquery,range,index,ALL。
一般来说,至少需要保证查询达到range级别,最好达到ref。
常见的几种类型:
- system
表只有一行记录,这是const类型的特列。 - const
当通过主键索引或唯一索引进行等值查询时出现:sql 1
2
3
4
5
6
7
8
9mysql> explain select b.* from bill b where b.id = 1;
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| 1 | SIMPLE | b | NULL | const | PRIMARY | PRIMARY | 4 | const | 1 | 100.00 | NULL |
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
1 row in set (0.02 sec)
mysql> - eq_ref
当通过主键索引或唯一索引进行关联查询时出现:sql 1
2
3
4
5
6
7
8
9
10mysql> explain select b.* from bill b left join user u on u.id = b.user_id;
+----+-------------+-------+------------+--------+---------------+---------+---------+----------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+--------+---------------+---------+---------+----------------+------+----------+-------------+
| 1 | SIMPLE | b | NULL | ALL | NULL | NULL | NULL | NULL | 3 | 100.00 | NULL |
| 1 | SIMPLE | u | NULL | eq_ref | PRIMARY | PRIMARY | 4 | test.b.user_id | 1 | 100.00 | Using index |
+----+-------------+-------+------------+--------+---------------+---------+---------+----------------+------+----------+-------------+
2 rows in set (0.02 sec)
mysql> - ref
当通过非唯一性索引进行等值查询或关联查询时出现:sql 1
2
3
4
5
6
7
8
9mysql> explain select b.* from bill b where b.user_id = 1;
+----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+-------+
| 1 | SIMPLE | b | NULL | ref | idx_user_id | idx_user_id | 5 | const | 2 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+-------+
1 row in set (0.02 sec)
mysql> - range
当通过索引进行范围查询时出现:sql 1
2
3
4
5
6
7
8
9mysql> explain select b.* from bill b where b.user_id > 1;
+----+-------------+-------+------------+-------+---------------+-------------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+-------------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | b | NULL | range | idx_user_id | idx_user_id | 5 | NULL | 1 | 100.00 | Using index condition |
+----+-------------+-------+------------+-------+---------------+-------------+---------+------+------+----------+-----------------------+
1 row in set (0.02 sec)
mysql> - index
当通过遍历索引查询时出现:sql 1
2
3
4
5
6
7
8
9mysql> explain select b.id from bill b;
+----+-------------+-------+------------+-------+---------------+-------------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+-------------+---------+------+------+----------+-------------+
| 1 | SIMPLE | b | NULL | index | NULL | idx_user_id | 5 | NULL | 3 | 100.00 | Using index |
+----+-------------+-------+------------+-------+---------------+-------------+---------+------+------+----------+-------------+
1 row in set (0.02 sec)
mysql> - ALL
当通过遍历全表查询时出现:sql 1
2
3
4
5
6
7
8
9mysql> explain select b.* from bill b;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+
| 1 | SIMPLE | b | NULL | ALL | NULL | NULL | NULL | NULL | 3 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+
1 row in set (0.02 sec)
mysql>
4.3.4.6 possible_keys
可能使用的索引,一个或多个。
查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被查询实际使用。
4.3.4.7 key
实际使用的索引。如果为NULL,则没有使用索引。
4.3.4.8 key_len
查询使用的索引字节数,可通过该列检查使用的索引长度,取值越大越好。
4.3.4.9 ref
显示索引的哪些列或常量被用于查找。
4.3.4.10 rows
根据表统计信息及索引选用情况,大致估算出找到所需的记录所需要读取的行数,取值越小越好。
4.3.4.11 filtered
经过搜索条件过滤后剩余记录条数的百分比。
4.3.4.12 Extra
包含不适合在其他列中显示但十分重要的额外信息。
常见取值:
- No tables used
查询没有使用FROM指定表:sql 1
2
3
4
5
6
7
8
9mysql> explain select 1 + 1;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------+
| 1 | SIMPLE | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | No tables used |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------+
1 row in set (0.05 sec)
mysql> - Zero limit
查询使用LIMIT指定0进行查询:sql 1
2
3
4
5
6
7
8
9mysql> explain select b.* from bill b limit 0;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+------------+
| 1 | SIMPLE | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | Zero limit |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+------------+
1 row in set (0.01 sec)
mysql> - Using index
查询的列被索引覆盖,不需要回表查询:sql 1
2
3
4
5
6
7
8
9mysql> explain select b.id from bill b;
+----+-------------+-------+------------+-------+---------------+-------------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+-------------+---------+------+------+----------+-------------+
| 1 | SIMPLE | b | NULL | index | NULL | idx_user_id | 5 | NULL | 3 | 100.00 | Using index |
+----+-------------+-------+------------+-------+---------------+-------------+---------+------+------+----------+-------------+
1 row in set (0.02 sec)
mysql> - Using index condition
查询的列没有被索引覆盖,需要回表查询,不能完全使用索引:sql 1
2
3
4
5
6
7
8
9mysql> explain select b.* from bill b where b.user_id > 1;
+----+-------------+-------+------------+-------+---------------+-------------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+-------------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | b | NULL | range | idx_user_id | idx_user_id | 5 | NULL | 1 | 100.00 | Using index condition |
+----+-------------+-------+------------+-------+---------------+-------------+---------+------+------+----------+-----------------------+
1 row in set (0.02 sec)
mysql> - Using where
查询的WHERE条件没有使用索引,需要进行全表扫描:sql 1
2
3
4
5
6
7
8
9mysql> explain select b.* from bill b where b.receiver = '张三';
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | b | NULL | ALL | NULL | NULL | NULL | NULL | 3 | 33.33 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
1 row in set (0.04 sec)
mysql> - Impossible WHERE
查询的WHERE条件总是失败,永远不可能获取到数据:sql 1
2
3
4
5
6
7
8
9mysql> explain select b.* from bill b where b.id = 1 and b.id = 2;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+------------------+
| 1 | SIMPLE | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | Impossible WHERE |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+------------------+
1 row in set (0.05 sec)
mysql> - Using filesort
出现文件排序,无法利用索引完成排序,比如没有通过索引字段排序或者出现了回表查询:sql 1
2
3
4
5
6
7
8
9mysql> explain select b.* from bill b order by b.bill_no;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------+
| 1 | SIMPLE | b | NULL | ALL | NULL | NULL | NULL | NULL | 3 | 100.00 | Using filesort |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------+
1 row in set (0.02 sec)
mysql> - Using temporary
使了用临时表保存中间结果:sql 1
2
3
4
5
6
7
8
9mysql> explain select distinct b.receiver from bill b;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-----------------+
| 1 | SIMPLE | b | NULL | ALL | NULL | NULL | NULL | NULL | 2 | 100.00 | Using temporary |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-----------------+
1 row in set (0.02 sec)
mysql> - Using join buffer (Block Nested Loop)
使用连接查询时,被驱动表不能使用索引,借用了连接缓冲区,发生了嵌套循环:sql 1
2
3
4
5
6
7
8
9
10mysql> explain select b.* from bill b, bill_detail bd where b.id = bd.bill_id;
+----+-------------+-------+------------+-------+---------------+-------------+---------+------+------+----------+----------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+-------------+---------+------+------+----------+----------------------------------------------------+
| 1 | SIMPLE | bd | NULL | index | idx_bill_id | idx_bill_id | 5 | NULL | 4 | 100.00 | Using index |
| 1 | SIMPLE | b | NULL | ALL | PRIMARY | NULL | NULL | NULL | 3 | 50.00 | Using where; Using join buffer (Block Nested Loop) |
+----+-------------+-------+------------+-------+---------------+-------------+---------+------+------+----------+----------------------------------------------------+
2 rows in set (0.02 sec)
mysql>
条