摘要:本文学习了常见的集合类及相关工具类,以及如何遍历集合。
环境
Windows 10 企业版 LTSC 21H2
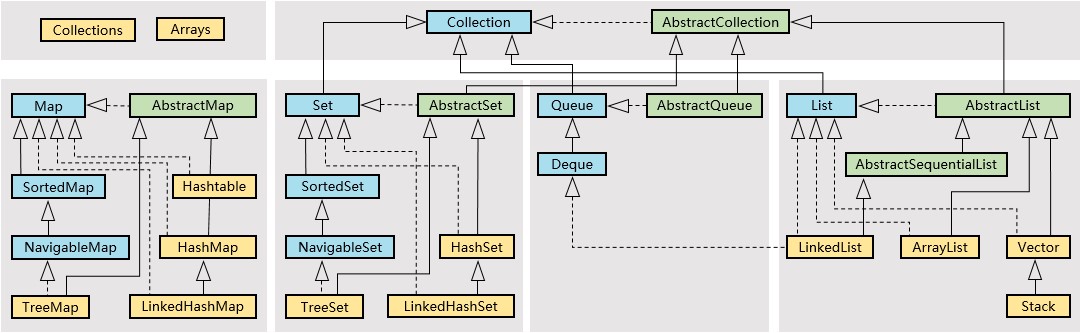
1 概述 类图:
所有集合类都位于java.util包下,集合类主要由Collection和Map这两个根接口派生而出:
接口用蓝色表示,表示不同集合类型,是集合框架的基础。例如Collection,Map,List,Set,Iterator等。
抽象类用绿色表示,对接口的部分实现。例如AbstractMap,AbstractCollection,AbstractList,AbstractSet等。
实现类用黄色表示,对接口的具体实现。例如ArrayList,LinkedList,HashSet,HashMap等。
1.1 集合类 集合容器框架中主要有四大类别:List、Set、Queue、Map。
List、Set、Queue继承了Collection接口,Map是和Collection同级别的顶层接口。
1.1.1 List List接口代表数组,允许插入重复的元素,是有序的集合,可以通过索引访问元素。
常用实现类有ArrayList和LinkedList,还有不常用的Vector。
另外,LinkedList还实现了Queue接口,因此也可以作为队列使用。
1.1.2 Set Set接口代表集合,不允许插入重复的元素,是无序的集合。
常用实现类有HashSet、LinkedHashSet和TreeSet,HashSet是通过Map中的HashMap实现的,LinkedHashSet是HashSet的子类,TreeSet是通过Map中的TreeMap实现的。
另外,TreeSet还实现了SortedSet接口,是有序的集合。
1.1.3 Queue Queue接口代表队列,遵循先入先出的原则,只允许在表的前端进行删除操作,而在表的后端进行插入操作。
常用实现类有LinkedList。
1.1.4 Map Map接口代表键值对集合,是保存了key-value键值对的集合,属于双列集合,根据每个键值对的键访问值。
常用实现类有HashMap、LinkedHashMap和TreeMap,还有不常用的Hashtable。
1.2 工具类 在集合框架中,除了有集合类之外,还有两个工具类,分别是处理集合的Collections类和处理数组的Arrays类。
2 集合类 2.1 ArrayList 2.1.1 简介 最常用的集合,允许任何符合规则的元素插入,包括null和重复元素。
底层是数组结构,提供了索引机制,查找效率高,增删效率低。
线程不安全。
2.1.2 扩容 数组结构会有容量的概念,ArrayList的初始容量默认为10,负载因子是1,表示当插入元素后个数超出原有长度时会进行扩增,扩容增量是0.5,所以扩增后容量为1.5倍,可使用方法手动扩容和缩减。
最好指定初始容量值,避免过多的进行扩容操作而浪费时间和效率。
2.1.3 方法 构造方法:
java 1 2 3 4 5 6 public ArrayList () ;public ArrayList (int initialCapacity) ;public ArrayList (Collection<? extends E> c) ;
常用方法:
java 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public int size () ;public boolean isEmpty () ;public boolean contains (Object o) ;public int indexOf (Object o) ;public int lastIndexOf (Object o) ;public E get (int index) ;public E set (int index, E element) ;public boolean add (E e) ;public void add (int index, E element) ;public E remove (int index) ;public boolean remove (Object o) ;
2.1.4 源码 2.1.4.1 属性 属性源码:
java 1 2 3 4 5 6 7 8 9 10 private static final int DEFAULT_CAPACITY = 10 ;private static final Object[] EMPTY_ELEMENTDATA = {};private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};transient Object[] elementData;private int size;
2.1.4.2 构造方法 构造方法源码:
java 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 public ArrayList () { this .elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA; } public ArrayList (int initialCapacity) { if (initialCapacity > 0 ) { this .elementData = new Object [initialCapacity]; } else if (initialCapacity == 0 ) { this .elementData = EMPTY_ELEMENTDATA; } else { throw new IllegalArgumentException ("Illegal Capacity: " +initialCapacity); } } public ArrayList (Collection<? extends E> c) { elementData = c.toArray(); if ((size = elementData.length) != 0 ) { if (elementData.getClass() != Object[].class) elementData = Arrays.copyOf(elementData, size, Object[].class); } else { this .elementData = EMPTY_ELEMENTDATA; } }
2.1.4.3 常用方法 常用方法源码:
java 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 public int size () { return size; } public boolean isEmpty () { return size == 0 ; } public boolean contains (Object o) { return indexOf(o) >= 0 ; } public int indexOf (Object o) { if (o == null ) { for (int i = 0 ; i < size; i++) if (elementData[i] == null ) return i; } else { for (int i = 0 ; i < size; i++) if (o.equals(elementData[i])) return i; } return -1 ; } public int lastIndexOf (Object o) { if (o == null ) { for (int i = size-1 ; i >= 0 ; i--) if (elementData[i] == null ) return i; } else { for (int i = size-1 ; i >= 0 ; i--) if (o.equals(elementData[i])) return i; } return -1 ; } public E get (int index) { rangeCheck(index); return elementData(index); } public E set (int index, E element) { rangeCheck(index); E oldValue = elementData(index); elementData[index] = element; return oldValue; } public boolean add (E e) { ensureCapacityInternal(size + 1 ); elementData[size++] = e; return true ; } public void add (int index, E element) { rangeCheckForAdd(index); ensureCapacityInternal(size + 1 ); System.arraycopy(elementData, index, elementData, index + 1 , size - index); elementData[index] = element; size++; } public E remove (int index) { rangeCheck(index); modCount++; E oldValue = elementData(index); int numMoved = size - index - 1 ; if (numMoved > 0 ) System.arraycopy(elementData, index+1 , elementData, index, numMoved); elementData[--size] = null ; return oldValue; } public boolean remove (Object o) { if (o == null ) { for (int index = 0 ; index < size; index++) if (elementData[index] == null ) { fastRemove(index); return true ; } } else { for (int index = 0 ; index < size; index++) if (o.equals(elementData[index])) { fastRemove(index); return true ; } } return false ; } private void fastRemove (int index) { modCount++; int numMoved = size - index - 1 ; if (numMoved > 0 ) System.arraycopy(elementData, index+1 , elementData, index, numMoved); elementData[--size] = null ; }
2.1.4.4 扩容方法 扩容方法源码:
java 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 public void ensureCapacity (int minCapacity) { int minExpand = (elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA) ? 0 : DEFAULT_CAPACITY; if (minCapacity > minExpand) { ensureExplicitCapacity(minCapacity); } } private void ensureCapacityInternal (int minCapacity) { if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) { minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity); } ensureExplicitCapacity(minCapacity); } private void ensureExplicitCapacity (int minCapacity) { modCount++; if (minCapacity - elementData.length > 0 ) grow(minCapacity); } private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8 ;private void grow (int minCapacity) { int oldCapacity = elementData.length; int newCapacity = oldCapacity + (oldCapacity >> 1 ); if (newCapacity - minCapacity < 0 ) newCapacity = minCapacity; if (newCapacity - MAX_ARRAY_SIZE > 0 ) newCapacity = hugeCapacity(minCapacity); elementData = Arrays.copyOf(elementData, newCapacity); } private static int hugeCapacity (int minCapacity) { if (minCapacity < 0 ) throw new OutOfMemoryError (); return (minCapacity > MAX_ARRAY_SIZE) ? Integer.MAX_VALUE : MAX_ARRAY_SIZE; }
2.1.4.5 序列化方法 序列化方法源码:
java 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 private void writeObject (java.io.ObjectOutputStream s) throws java.io.IOException{ int expectedModCount = modCount; s.defaultWriteObject(); s.writeInt(size); for (int i=0 ; i<size; i++) { s.writeObject(elementData[i]); } if (modCount != expectedModCount) { throw new ConcurrentModificationException (); } } private void readObject (java.io.ObjectInputStream s) throws java.io.IOException, ClassNotFoundException { elementData = EMPTY_ELEMENTDATA; s.defaultReadObject(); s.readInt(); if (size > 0 ) { ensureCapacityInternal(size); Object[] a = elementData; for (int i=0 ; i<size; i++) { a[i] = s.readObject(); } } }
2.1.4.6 遍历方法 ArrayList提供了两种迭代器,实现了Iterator接口的Itr类,以及实现了ListIterator接口并继承了Itr类的ListItr类。
ListItr类对Itr类的方法进行了扩展,提供了添加和修改的方法,这里只学习Itr类。
遍历方法源码:
java 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 public Iterator<E> iterator () { return new Itr (); } private class Itr implements Iterator <E> { int cursor; int lastRet = -1 ; int expectedModCount = modCount; public boolean hasNext () { return cursor != size; } public E next () { checkForComodification(); int i = cursor; if (i >= size) throw new NoSuchElementException (); Object[] elementData = ArrayList.this .elementData; if (i >= elementData.length) throw new ConcurrentModificationException (); cursor = i + 1 ; return (E) elementData[lastRet = i]; } public void remove () { if (lastRet < 0 ) throw new IllegalStateException (); checkForComodification(); try { ArrayList.this .remove(lastRet); cursor = lastRet; lastRet = -1 ; expectedModCount = modCount; } catch (IndexOutOfBoundsException ex) { throw new ConcurrentModificationException (); } } @Override public void forEachRemaining (Consumer<? super E> consumer) { Objects.requireNonNull(consumer); final int size = ArrayList.this .size; int i = cursor; if (i >= size) { return ; } final Object[] elementData = ArrayList.this .elementData; if (i >= elementData.length) { throw new ConcurrentModificationException (); } while (i != size && modCount == expectedModCount) { consumer.accept((E) elementData[i++]); } cursor = i; lastRet = i - 1 ; checkForComodification(); } final void checkForComodification () { if (modCount != expectedModCount) throw new ConcurrentModificationException (); } }
2.1.5 补充 2.1.5.1 数组没有private 查看ArrayList的源码,发现内部定义的elementData数组并没有像size属性一样被private修饰,表示访问权限是默认的包权限,这么做的原因被写在了声明后面的注释里,即非私有的访问权限是为了简化嵌套类的访问。
如果想知道如何简化嵌套类的访问,就需要写一个例子并反编译进一步查看。
示例:
java 1 2 3 4 5 6 7 8 9 10 11 12 13 14 public class Demo { private int i = 1 ; public Inner inner = new Inner (); class Inner { public void in () { i = 5 ; } } public static void main (String[] args) { Demo demo = new Demo (); demo.inner.in(); System.out.println(demo.i); } }
反编译private修饰的代码:
java 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 static int access$002 (com.example.demo.Demo, int ); Code: 0 : aload_0 1 : iload_1 2 : dup_x1 3 : putfield #1 6 : ireturn LineNumberTable: line 3 : 0 LocalVariableTable: Start Length Slot Name Signature 0 7 0 x0 Lcom/example/demo/Demo; 0 7 1 x1 I public void in () ; Code: 0 : aload_0 1 : getfield #1 4 : iconst_5 5 : invokestatic #3 8 : pop 9 : return LineNumberTable: line 8 : 0 line 9 : 9 LocalVariableTable: Start Length Slot Name Signature 0 10 0 this Lcom/example/demo/Demo$Inner;
反编译没有private修饰的代码:
java 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public void in () ; Code: 0 : aload_0 1 : getfield #1 4 : iconst_5 5 : putfield #3 8 : return LineNumberTable: line 8 : 0 line 9 : 8 LocalVariableTable: Start Length Slot Name Signature 0 9 0 this Lcom/example/demo/Demo$Inner;
因此,去掉private修饰简化嵌套类的访问。
2.1.5.2 数组使用transient 查看ArrayList的源码,发现内部定义的elementData数组使用了transient修饰,transient表示该数组不参与序列化。
那ArrayList是如何实现序列化的呢?
这就涉及到了序列化的基础原理了,之前在学习输入输出流的时候,有一种元素流,主要的类是ObjectOutputStream和ObjectInputStream。
ObjectOutputStream类是用于序列化的输出流,ObjectInputStream类是用于反序列化的输入流。
在序列化和反序列化的时候,JVM会调用元素里的writeObject()方法和readObject()方法,进行用户自定义的序列化和反序列化。如果没有提供,调用ObjectOutputStream类的defaultWriteObject()方法和ObjectInputStream类的defaultReadObject()方法,进行默认的序列化和反序列化,这时就会忽略transient修饰的成员。
因此,在ArrayList内部自定义了writeObject()方法和readObject()方法,自定义序列化和反序列化,这么做是为了处理实际存储的元素,避免处理整个数组。
2.2 Vector 2.2.1 简介 不常用的集合,和ArrayList类似,允许任何符合规则的元素插入,包括null和重复元素。
底层是数组结构,提供了索引机制,查找效率高,增删效率低。
线程安全,使用了synchronized关键字。
2.2.2 扩容 扩容机制和ArrayList类似,初始容量默认为10,负载因子是1,表示当插入元素后个数超出原有长度时会进行扩增,扩容增量是默认为原容量,所以扩增后容量为2倍,可使用方法手动扩容和缩减。
最好指定初始容量值和增量,避免过多的进行扩容操作而浪费时间和效率。
2.2.3 方法 构造方法:
java 1 2 3 4 5 6 7 8 public Vector () ;public Vector (int initialCapacity) ;public Vector (int initialCapacity, int capacityIncrement) ;public Vector (Collection<? extends E> c) ;
常用方法:
java 1 2 3 4 5 6 7 8 9 10 11 12 public synchronized E get (int index) ;public synchronized E set (int index, E element) ;public synchronized boolean add (E e) ;public void add (int index, E element) ;public synchronized E remove (int index) ;public boolean remove (Object o) ;
2.2.4 源码 2.2.4.1 属性 属性源码:
java 1 2 3 4 5 6 protected Object[] elementData;protected int elementCount;protected int capacityIncrement;
2.2.4.2 构造方法 构造方法源码:
java 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 public Vector () { this (10 ); } public Vector (int initialCapacity) { this (initialCapacity, 0 ); } public Vector (int initialCapacity, int capacityIncrement) { super (); if (initialCapacity < 0 ) throw new IllegalArgumentException ("Illegal Capacity: " +initialCapacity); this .elementData = new Object [initialCapacity]; this .capacityIncrement = capacityIncrement; } public Vector (Collection<? extends E> c) { elementData = c.toArray(); elementCount = elementData.length; if (elementData.getClass() != Object[].class) elementData = Arrays.copyOf(elementData, elementCount, Object[].class); }
2.2.4.3 常用方法 常用方法源码:
java 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 public synchronized E get (int index) { if (index >= elementCount) throw new ArrayIndexOutOfBoundsException (index); return elementData(index); } public synchronized E set (int index, E element) { if (index >= elementCount) throw new ArrayIndexOutOfBoundsException (index); E oldValue = elementData(index); elementData[index] = element; return oldValue; } public synchronized boolean add (E e) { modCount++; ensureCapacityHelper(elementCount + 1 ); elementData[elementCount++] = e; return true ; } public void add (int index, E element) { insertElementAt(element, index); } public synchronized E remove (int index) { modCount++; if (index >= elementCount) throw new ArrayIndexOutOfBoundsException (index); E oldValue = elementData(index); int numMoved = elementCount - index - 1 ; if (numMoved > 0 ) System.arraycopy(elementData, index+1 , elementData, index, numMoved); elementData[--elementCount] = null ; return oldValue; } public boolean remove (Object o) { return removeElement(o); }
2.2.4.4 扩容方法 扩容方法源码:
java 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 public synchronized void ensureCapacity (int minCapacity) { if (minCapacity > 0 ) { modCount++; ensureCapacityHelper(minCapacity); } } private void ensureCapacityHelper (int minCapacity) { if (minCapacity - elementData.length > 0 ) grow(minCapacity); } private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8 ;private void grow (int minCapacity) { int oldCapacity = elementData.length; int newCapacity = oldCapacity + ((capacityIncrement > 0 ) ? capacityIncrement : oldCapacity); if (newCapacity - minCapacity < 0 ) newCapacity = minCapacity; if (newCapacity - MAX_ARRAY_SIZE > 0 ) newCapacity = hugeCapacity(minCapacity); elementData = Arrays.copyOf(elementData, newCapacity); } private static int hugeCapacity (int minCapacity) { if (minCapacity < 0 ) throw new OutOfMemoryError (); return (minCapacity > MAX_ARRAY_SIZE) ? Integer.MAX_VALUE : MAX_ARRAY_SIZE; }
2.3 Stack 2.3.1 简介 不常用的集合,继承自Vector,允许任何符合规则的元素插入,包括null和重复元素。
同Vector类似,底层是数组结构,但通过对Vector的扩展,将数组结构倒置形成堆栈结构,使用典型的后进先出操作方式。
线程安全,使用了synchronized关键字。
2.3.2 扩容 扩容同Vector。
2.3.3 方法 构造方法:
java 常用方法:
java 1 2 3 4 5 6 7 8 9 10 public boolean empty () ;public E push (E item) ;public synchronized E pop () ;public synchronized E peek () ;public synchronized int search (Object o) ;
2.3.4 源码 2.3.4.1 构造方法 构造方法源码:
java 2.3.4.2 常用方法 常用方法源码:
java 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 public boolean empty () { return size() == 0 ; } public E push (E item) { addElement(item); return item; } public synchronized E pop () { E obj; int len = size(); obj = peek(); removeElementAt(len - 1 ); return obj; } public synchronized E peek () { int len = size(); if (len == 0 ) throw new EmptyStackException (); return elementAt(len - 1 ); } public synchronized int search (Object o) { int i = lastIndexOf(o); if (i >= 0 ) { return size() - i; } return -1 ; }
2.4 LinkedList 2.4.1 简介 允许任何符合规则的元素插入,包括null和重复元素。
底层是双向链表结构,使用双向链表代替索引,查找效率低,增删效率高。
线程不安全。
2.4.2 方法 构造方法:
java 1 2 3 4 public LinkedList () ;public LinkedList (Collection<? extends E> c) ;
常用方法:
java 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public int size () ;public boolean contains (Object o) ;public int indexOf (Object o) ;public int lastIndexOf (Object o) ;public E get (int index) ;public E getFirst () ;public E getLast () ;public E set (int index, E element) ;public void add (int index, E element) ;public E remove (int index) ;
队列方法:
java 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 public boolean add (E e) ;public void addFirst (E e) ;public void addLast (E e) ;public boolean remove (Object o) ;public E removeFirst () ;public E removeLast () ;public E peek () ;public E peekFirst () ;public E peekLast () ;public boolean offer (E e) ;public boolean offerFirst (E e) ;public boolean offerLast (E e) ;public E poll () ;public E pollFirst () ;public E pollLast () ;
栈方法:
java 1 2 3 4 public void push (E e) ;public E pop () ;
2.4.3 源码 2.4.3.1 属性 属性源码:
java 1 2 3 4 5 6 transient int size = 0 ;transient Node<E> first;transient Node<E> last;
2.4.3.2 构造方法 构造方法源码:
java 1 2 3 4 5 6 7 8 public LinkedList () {} public LinkedList (Collection<? extends E> c) { this (); addAll(c); }
2.4.3.3 常用方法 常用方法源码:
java 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 public int size () { return size; } public boolean contains (Object o) { return indexOf(o) != -1 ; } public int indexOf (Object o) { int index = 0 ; if (o == null ) { for (Node<E> x = first; x != null ; x = x.next) { if (x.item == null ) return index; index++; } } else { for (Node<E> x = first; x != null ; x = x.next) { if (o.equals(x.item)) return index; index++; } } return -1 ; } public int lastIndexOf (Object o) { int index = size; if (o == null ) { for (Node<E> x = last; x != null ; x = x.prev) { index--; if (x.item == null ) return index; } } else { for (Node<E> x = last; x != null ; x = x.prev) { index--; if (o.equals(x.item)) return index; } } return -1 ; } public E get (int index) { checkElementIndex(index); return node(index).item; } public E getFirst () { final Node<E> f = first; if (f == null ) throw new NoSuchElementException (); return f.item; } public E getLast () { final Node<E> l = last; if (l == null ) throw new NoSuchElementException (); return l.item; } public E set (int index, E element) { checkElementIndex(index); Node<E> x = node(index); E oldVal = x.item; x.item = element; return oldVal; } public void add (int index, E element) { checkPositionIndex(index); if (index == size) linkLast(element); else linkBefore(element, node(index)); } public E remove (int index) { checkElementIndex(index); return unlink(node(index)); }
2.4.3.4 队列方法 队列方法源码:
java 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 public boolean add (E e) { linkLast(e); return true ; } public void addFirst (E e) { linkFirst(e); } public void addLast (E e) { linkLast(e); } public boolean remove (Object o) { if (o == null ) { for (Node<E> x = first; x != null ; x = x.next) { if (x.item == null ) { unlink(x); return true ; } } } else { for (Node<E> x = first; x != null ; x = x.next) { if (o.equals(x.item)) { unlink(x); return true ; } } } return false ; } public E removeFirst () { final Node<E> f = first; if (f == null ) throw new NoSuchElementException (); return unlinkFirst(f); } public E removeLast () { final Node<E> l = last; if (l == null ) throw new NoSuchElementException (); return unlinkLast(l); } public E peek () { final Node<E> f = first; return (f == null ) ? null : f.item; } public E peekFirst () { final Node<E> f = first; return (f == null ) ? null : f.item; } public E peekLast () { final Node<E> l = last; return (l == null ) ? null : l.item; } public boolean offer (E e) { return add(e); } public boolean offerFirst (E e) { addFirst(e); return true ; } public boolean offerLast (E e) { addLast(e); return true ; } public E poll () { final Node<E> f = first; return (f == null ) ? null : unlinkFirst(f); } public E pollFirst () { final Node<E> f = first; return (f == null ) ? null : unlinkFirst(f); } public E pollLast () { final Node<E> l = last; return (l == null ) ? null : unlinkLast(l); }
2.4.3.5 栈方法 栈方法源码:
java 1 2 3 4 5 6 7 8 public void push (E e) { addFirst(e); } public E pop () { return removeFirst(); }
2.5 HashSet 2.5.1 简介 不允许重复的元素插入,可以插入null。
底层是HashMap,不能保证插入和输出的顺序一致。
线程不安全。
2.5.2 扩容 扩容同HashMap。
2.5.3 方法 构造方法:
java 1 2 3 4 5 6 7 8 9 10 public HashSet () ;public HashSet (int initialCapacity) ;public HashSet (int initialCapacity, float loadFactor) ;public HashSet (Collection<? extends E> c) ;HashSet(int initialCapacity, float loadFactor, boolean dummy);
常用方法:
java 1 2 3 4 5 6 7 8 9 10 11 12 public int size () ;public boolean isEmpty () ;public boolean contains (Object o) ;public boolean add (E e) ;public boolean remove (Object o) ;public void clear () ;
2.5.4 源码 2.5.4.1 属性 属性源码:
java 1 2 3 4 private transient HashMap<E,Object> map;private static final Object PRESENT = new Object ();
2.5.4.2 构造方法 构造方法源码:
java 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 public HashSet () { map = new HashMap <>(); } public HashSet (int initialCapacity) { map = new HashMap <>(initialCapacity); } public HashSet (int initialCapacity, float loadFactor) { map = new HashMap <>(initialCapacity, loadFactor); } public HashSet (Collection<? extends E> c) { map = new HashMap <>(Math.max((int ) (c.size()/.75f ) + 1 , 16 )); addAll(c); } HashSet(int initialCapacity, float loadFactor, boolean dummy) { map = new LinkedHashMap <>(initialCapacity, loadFactor); }
2.5.4.3 常用方法 常用方法源码:
java 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 public int size () { return map.size(); } public boolean isEmpty () { return map.isEmpty(); } public boolean contains (Object o) { return map.containsKey(o); } public boolean add (E e) { return map.put(e, PRESENT) == null ; } public boolean remove (Object o) { return map.remove(o) == PRESENT; } public void clear () { map.clear(); }
2.6 LinkedHashSet 2.6.1 简介 不允许重复的元素插入,可以插入null。
继承自HashSet,底层是LinkedHashMap,维护了元素的插入顺序。
线程不安全。
2.6.2 扩容 扩容同LinkedHashMap。
2.6.3 方法 构造方法:
java 1 2 3 4 5 6 7 8 public LinkedHashSet (int initialCapacity, float loadFactor) ;public LinkedHashSet (int initialCapacity) ;public LinkedHashSet () ;public LinkedHashSet (Collection<? extends E> c) ;
常用方法同HashSet。
2.6.4 源码 2.6.4.1 属性 属性同HashSet。
2.6.4.2 构造方法 构造方法源码:
java 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public LinkedHashSet (int initialCapacity, float loadFactor) { super (initialCapacity, loadFactor, true ); } public LinkedHashSet (int initialCapacity) { super (initialCapacity, .75f , true ); } public LinkedHashSet () { super (16 , .75f , true ); } public LinkedHashSet (Collection<? extends E> c) { super (Math.max(2 *c.size(), 11 ), .75f , true ); addAll(c); }
2.6.4.3 常用方法 常用方法同HashSet。
2.7 TreeSet 2.7.1 简介 不允许重复的元素插入,不可以插入null。
底层TreeMap,使用二叉树结构存储元素,支持自然排序和定制排序。
线程不安全。
2.7.2 扩容 扩容同TreeMap。
2.7.3 方法 构造方法:
java 1 2 3 4 5 6 7 8 9 10 TreeSet(NavigableMap<E,Object> m); public TreeSet () ;public TreeSet (Comparator<? super E> comparator) ;public TreeSet (Collection<? extends E> c) ;public TreeSet (SortedSet<E> s) ;
常用方法:
java 1 2 3 4 5 6 7 8 9 10 11 12 public int size () ;public boolean isEmpty () ;public boolean contains (Object o) ;public boolean add (E e) ;public boolean remove (Object o) ;public void clear () ;
2.7.4 源码 2.7.4.1 属性 属性源码:
java 1 2 3 4 private transient NavigableMap<E,Object> m;private static final Object PRESENT = new Object ();
2.7.4.2 构造方法 构造方法源码:
java 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 TreeSet(NavigableMap<E,Object> m) { this .m = m; } public TreeSet () { this (new TreeMap <E,Object>()); } public TreeSet (Comparator<? super E> comparator) { this (new TreeMap <>(comparator)); } public TreeSet (Collection<? extends E> c) { this (); addAll(c); } public TreeSet (SortedSet<E> s) { this (s.comparator()); addAll(s); }
2.7.4.3 常用方法 常用方法源码:
java 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 public int size () { return m.size(); } public boolean isEmpty () { return m.isEmpty(); } public boolean contains (Object o) { return m.containsKey(o); } public boolean add (E e) { return m.put(e, PRESENT) == null ; } public boolean remove (Object o) { return m.remove(o) == PRESENT; } public void clear () { m.clear(); }
2.8 HashMap 2.8.1 简介 不允许插入key值相同的元素,允许插入null的key值。
底层由数组、链表、红黑树组成,数组中存储链表或红黑树,将一个key到value的映射作为一个元素,不能保证插入顺序和输出顺序一致。
线程不安全。
2.8.2 扩容 数组结构会有容量的概念,HashMap的默认容量为16,默认负载因子是0.75,表示当插入元素后个数超出长度的0.75倍时会进行扩增,默认扩容增量是1,所以扩增后容量为2倍。
最好指定初始容量值,避免过多的进行扩容操作而浪费时间和效率。
2.8.3 方法 构造方法:
java 1 2 3 4 5 6 7 8 public HashMap (int initialCapacity, float loadFactor) ;public HashMap (int initialCapacity) ;public HashMap () ;public HashMap (Map<? extends K, ? extends V> m) ;
常用方法:
java 1 2 3 4 5 6 7 8 9 10 11 12 public int size () ;public boolean isEmpty () ;public V get (Object key) ;public V put (K key, V value) ;public V remove (Object key) ;public void clear () ;
2.8.4 源码 2.8.4.1 属性 静态属性源码:
java 1 2 3 4 5 6 7 8 9 10 11 12 static final int DEFAULT_INITIAL_CAPACITY = 1 << 4 ;static final int MAXIMUM_CAPACITY = 1 << 30 ;static final float DEFAULT_LOAD_FACTOR = 0.75f ;static final int TREEIFY_THRESHOLD = 8 ;static final int UNTREEIFY_THRESHOLD = 6 ;static final int MIN_TREEIFY_CAPACITY = 64 ;
普通属性源码:
java 1 2 3 4 5 6 7 8 9 10 11 12 transient Node<K,V>[] table;transient Set<Map.Entry<K,V>> entrySet;transient int size;transient int modCount;int threshold;final float loadFactor;
2.8.4.2 工具方法 工具方法源码:
java 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 static final int hash (Object key) { int h; return (key == null ) ? 0 : (h = key.hashCode()) ^ (h >>> 16 ); } static final int tableSizeFor (int cap) { int n = cap - 1 ; n |= n >>> 1 ; n |= n >>> 2 ; n |= n >>> 4 ; n |= n >>> 8 ; n |= n >>> 16 ; return (n < 0 ) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1 ; }
2.8.4.3 构造方法 构造方法源码:
java 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 public HashMap (int initialCapacity, float loadFactor) { if (initialCapacity < 0 ) throw new IllegalArgumentException ("Illegal initial capacity: " + initialCapacity); if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; if (loadFactor <= 0 || Float.isNaN(loadFactor)) throw new IllegalArgumentException ("Illegal load factor: " + loadFactor); this .loadFactor = loadFactor; this .threshold = tableSizeFor(initialCapacity); } public HashMap (int initialCapacity) { this (initialCapacity, DEFAULT_LOAD_FACTOR); } public HashMap () { this .loadFactor = DEFAULT_LOAD_FACTOR; } public HashMap (Map<? extends K, ? extends V> m) { this .loadFactor = DEFAULT_LOAD_FACTOR; putMapEntries(m, false ); }
2.8.4.4 常用方法 常用方法源码:
java 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 public int size () { return size; } public boolean isEmpty () { return size == 0 ; } public V get (Object key) { Node<K,V> e; return (e = getNode(hash(key), key)) == null ? null : e.value; } final Node<K,V> getNode (int hash, Object key) { Node<K,V>[] tab; Node<K,V> first, e; int n; K k; if ((tab = table) != null && (n = tab.length) > 0 && (first = tab[(n - 1 ) & hash]) != null ) { if (first.hash == hash && ((k = first.key) == key || (key != null && key.equals(k)))) return first; if ((e = first.next) != null ) { if (first instanceof TreeNode) return ((TreeNode<K,V>)first).getTreeNode(hash, key); do { if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) return e; } while ((e = e.next) != null ); } } return null ; } public V put (K key, V value) { return putVal(hash(key), key, value, false , true ); } final V putVal (int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; if ((tab = table) == null || (n = tab.length) == 0 ) n = (tab = resize()).length if ((p = tab[i = (n - 1 ) & hash]) == null ) tab[i] = newNode(hash, key, value, null ); else { Node<K,V> e; K k; if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this , tab, hash, key, value); else { for (int binCount = 0 ; ; ++binCount) { if ((e = p.next) == null ) { p.next = newNode(hash, key, value, null ); if (binCount >= TREEIFY_THRESHOLD - 1 ) treeifyBin(tab, hash); break ; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break ; p = e; } } if (e != null ) { V oldValue = e.value; if (!onlyIfAbsent || oldValue == null ) e.value = value; afterNodeAccess(e); return oldValue; } } ++modCount; if (++size > threshold) resize(); afterNodeInsertion(evict); return null ; } public V remove (Object key) { Node<K,V> e; return (e = removeNode(hash(key), key, null , false , true )) == null ? null : e.value; } final Node<K,V> removeNode (int hash, Object key, Object value, boolean matchValue, boolean movable) { Node<K,V>[] tab; Node<K,V> p; int n, index; if ((tab = table) != null && (n = tab.length) > 0 && (p = tab[index = (n - 1 ) & hash]) != null ) { Node<K,V> node = null , e; K k; V v; if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) node = p; else if ((e = p.next) != null ) { if (p instanceof TreeNode) node = ((TreeNode<K,V>)p).getTreeNode(hash, key); else { do { if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) { node = e; break ; } p = e; } while ((e = e.next) != null ); } } if (node != null && (!matchValue || (v = node.value) == value || (value != null && value.equals(v)))) { if (node instanceof TreeNode) ((TreeNode<K,V>)node).removeTreeNode(this , tab, movable); else if (node == p) tab[index] = node.next; else p.next = node.next; ++modCount; --size; afterNodeRemoval(node); return node; } } return null ; } public void clear () { Node<K,V>[] tab; modCount++; if ((tab = table) != null && size > 0 ) { size = 0 ; for (int i = 0 ; i < tab.length; ++i) tab[i] = null ; } }
2.8.4.5 扩容方法 扩容方法源码:
java 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 final Node<K,V>[] resize() { Node<K,V>[] oldTab = table; int oldCap = (oldTab == null ) ? 0 : oldTab.length; int oldThr = threshold; int newCap, newThr = 0 ; if (oldCap > 0 ) { if (oldCap >= MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return oldTab; } else if ((newCap = oldCap << 1 ) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY) newThr = oldThr << 1 ; } else if (oldThr > 0 ) newCap = oldThr; else { newCap = DEFAULT_INITIAL_CAPACITY; newThr = (int )(DEFAULT_LOAD_FACTOR *DEFAULT_INITIAL_CAPACITY); } if (newThr == 0 ) { float ft = (float )newCap* loadFactor; newThr = (newCap < MAXIMUM_CAPACITY && ft < (float )MAXIMUM_CAPACITY ? (int )ft : Integer.MAX_VALUE); } threshold = newThr; Node<K,V>[] newTab = (Node<K,V>[])new Node [newCap]; table = newTab; if (oldTab != null ) { for (int j = 0 ; j < oldCap; ++j) { Node<K,V> e; if ((e = oldTab[j]) != null ) { oldTab[j] = null ; if (e.next == null ) newTab[e.hash & (newCap - 1 )] = e; else if (e instanceof TreeNode) ((TreeNode<K,V>)e).split(this , newTab, j, oldCap); else { Node<K,V> loHead = null , loTail = null ; Node<K,V> hiHead = null , hiTail = null ; Node<K,V> next; do { next = e.next; if ((e.hash & oldCap) == 0 ) { if (loTail == null ) loHead = e; else loTail.next = e; loTail = e; } else { if (hiTail == null ) hiHead = e; else hiTail.next = e; hiTail = e; } } while ((e = next) != null ); if (loTail != null ) { loTail.next = null ; newTab[j] = loHead; } if (hiTail != null ) { hiTail.next = null ; newTab[j + oldCap] = hiHead; } } } } } return newTab; }
2.8.5 补充 2.8.5.1 为什么数组长度是2的倍数 长度减一后的二进制位全为1,可以用来计算节点在数组中的位置,不会造成浪费。
如果指定长度不是2的倍数,在构造方法中的最后一步会根据指定长度计算容量,会通过移位运算得到大于等于指定长度的,并且为2的倍数的最小正整数。
2.8.5.2 为什么不直接使用equals方法比较 在Object类中有一个hashCode()方法,用来获取元素的哈希值,也被称作为散列值。
使用native修饰hashCode()方法,意味着这个方法和平台有关。大多数情况下hashCode()方法返回的是与元素信息(存储地址和字段等)有关的数值。
当向集合中插入元素时,如果调用equals()逐个进行比较,虽然可行但是这样做的效率很低。因此,先调用hashCode()进行判断,如果相同再调用equals()判断,就会提高效率。
2.8.5.3 为什么要使用hash方法处理hashCode 在计算节点在数组中的位置时,一般是通过与节点有关的数值除以数组长度取余得到的。当数组长度为2的倍数时,取余操作相当于数值同数组长度减一进行与运算。
根据数组长度减一得到的结果,将二进制位分为高位和低位,将左边全为0的部分作为高位,将右边全为1的部分作为低位。在与运算时,任何数字与0相与只能得到0,所以高位无效,只用到了低位。
如果使用hashCode进行与运算,两个hashCode不同但是低位相同的节点会被分到一个数组中,哈希碰撞发生的可能性较大。因此,需要对hashCode进行处理,使两个高位不同低位相同的节点得到的结果也不同。
可以将hash()方法称为扰动函数,是用来对hashCode进行处理的方法。在hash()方法处理后,hashCode高位的变化也会影响低位,这时再使用低位计算位置就能使元素的分布更加合理,哈希碰撞的可能性也会降低。
在JDK1.8版本中,只使用了hashCode进行了一次与运算:
java 1 2 3 4 static final int hash (Object key) { int h; return (key == null ) ? 0 : (h = key.hashCode()) ^ (h >>> 16 ); }
2.8.5.4 什么时候进行扩容 扩容有两个触发时机:
插入第一个节点时,初始化数组时进行扩容。
插入节点后,长度超过阈值时进行扩容。
2.8.5.5 如何对链表扩容 使用高低位链表,将节点的hash值同原数组长度进行与运算,根据结果0和1放到低位链表和高位链表。
将低位链表放置到新数组的低位,将高位链表放置到新数组的高位,低位的位置加上原数组长度就是高位的位置。
2.8.5.6 为什么要同时重写equals方法和hashCode方法 一般在重写equals()方法的时候,也会尽量重写hashCode()方法,就是为了在equals()方法判断相等的时候保证让hashCode()方法判断相等。
2.9 Hashtable 2.9.1 简介 不允许插入key值相同的元素,不允许插入null的key值,不允许插入null的value值。
底层由数组、链表组成,数组中存储链表,通过单链表解决哈希冲突。
线程安全,使用了synchronized关键字。
2.9.2 扩容 默认容量为11,默认负载因子是0.75,扩增后容量为2倍加1。
2.9.3 方法 构造方法:
java 1 2 3 4 5 6 7 8 public Hashtable (int initialCapacity, float loadFactor) ;public Hashtable (int initialCapacity) ;public Hashtable () ;public Hashtable (Map<? extends K, ? extends V> t) ;
常用方法:
java 1 2 3 4 5 6 7 8 9 10 public synchronized int size () ;public synchronized boolean isEmpty () ;public synchronized V get (Object key) ;public synchronized V put (K key, V value) ;public synchronized V remove (Object key) ;
2.9.4 源码 2.9.4.1 属性 属性源码:
java 1 2 3 4 5 6 7 8 9 10 private transient Entry<?,?>[] table;private transient int count;private int threshold;private float loadFactor;private transient int modCount = 0 ;
2.9.4.2 构造方法 构造方法源码:
java 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 public Hashtable (int initialCapacity, float loadFactor) { if (initialCapacity < 0 ) throw new IllegalArgumentException ("Illegal Capacity: " + initialCapacity); if (loadFactor <= 0 || Float.isNaN(loadFactor)) throw new IllegalArgumentException ("Illegal Load: " +loadFactor); if (initialCapacity == 0 ) initialCapacity = 1 ; this .loadFactor = loadFactor; table = new Entry <?,?>[initialCapacity]; threshold = (int )Math.min(initialCapacity * loadFactor, MAX_ARRAY_SIZE + 1 ); } public Hashtable (int initialCapacity) { this (initialCapacity, 0.75f ); } public Hashtable () { this (11 , 0.75f ); } public Hashtable (Map<? extends K, ? extends V> t) { this (Math.max(2 *t.size(), 11 ), 0.75f ); putAll(t); }
2.9.4.3 常用方法 常用方法源码:
java 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 public synchronized int size () { return count; } public synchronized boolean isEmpty () { return count == 0 ; } public synchronized V get (Object key) { Entry<?,?> tab[] = table; int hash = key.hashCode(); int index = (hash & 0x7FFFFFFF ) % tab.length; for (Entry<?,?> e = tab[index] ; e != null ; e = e.next) { if ((e.hash == hash) && e.key.equals(key)) { return (V)e.value; } } return null ; } public synchronized V put (K key, V value) { if (value == null ) { throw new NullPointerException (); } Entry<?,?> tab[] = table; int hash = key.hashCode(); int index = (hash & 0x7FFFFFFF ) % tab.length; Entry<K,V> entry = (Entry<K,V>)tab[index]; for (; entry != null ; entry = entry.next) { if ((entry.hash == hash) && entry.key.equals(key)) { V old = entry.value; entry.value = value; return old; } } addEntry(hash, key, value, index); return null ; } private void addEntry (int hash, K key, V value, int index) { modCount++; Entry<?,?> tab[] = table; if (count >= threshold) { rehash(); tab = table; hash = key.hashCode(); index = (hash & 0x7FFFFFFF ) % tab.length; } Entry<K,V> e = (Entry<K,V>) tab[index]; tab[index] = new Entry <>(hash, key, value, e); count++; } public synchronized V remove (Object key) { Entry<?,?> tab[] = table; int hash = key.hashCode(); int index = (hash & 0x7FFFFFFF ) % tab.length; Entry<K,V> e = (Entry<K,V>)tab[index]; for (Entry<K,V> prev = null ; e != null ; prev = e, e = e.next) { if ((e.hash == hash) && e.key.equals(key)) { modCount++; if (prev != null ) { prev.next = e.next; } else { tab[index] = e.next; } count--; V oldValue = e.value; e.value = null ; return oldValue; } } return null ; }
2.9.4.4 扩容方法 扩容方法源码:
java 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8 ;protected void rehash () { int oldCapacity = table.length; Entry<?,?>[] oldMap = table; int newCapacity = (oldCapacity << 1 ) + 1 ; if (newCapacity - MAX_ARRAY_SIZE > 0 ) { if (oldCapacity == MAX_ARRAY_SIZE) return ; newCapacity = MAX_ARRAY_SIZE; } Entry<?,?>[] newMap = new Entry <?,?>[newCapacity]; modCount++; threshold = (int )Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1 ); table = newMap; for (int i = oldCapacity ; i-- > 0 ;) { for (Entry<K,V> old = (Entry<K,V>)oldMap[i] ; old != null ; ) { Entry<K,V> e = old; old = old.next; int index = (e.hash & 0x7FFFFFFF ) % newCapacity; e.next = (Entry<K,V>)newMap[index]; newMap[index] = e; } } }
2.10 LinkedHashMap 2.10.1 简介 不允许插入key值相同的元素,允许插入null的key值。
继承自HashMap,底层由数组、链表、红黑树组成。在此基础上,新增了双向链表,连接了集合中的所有节点,维护了节点的插入顺序。
线程不安全。
2.10.2 扩容 扩容同HashMap。
2.10.3 方法 构造方法:
java 1 2 3 4 5 6 7 8 9 10 public LinkedHashMap (int initialCapacity, float loadFactor) ;public LinkedHashMap (int initialCapacity) ;public LinkedHashMap () ;public LinkedHashMap (Map<? extends K, ? extends V> m) ;public LinkedHashMap (int initialCapacity, float loadFactor, boolean accessOrder) ;
常用方法同HashMap。
2.10.4 源码 2.10.4.1 扩展节点 在LinkedHashMap中,对HashMap的节点进行了扩展,在节点中维护了插入顺序:
java 1 2 3 4 5 6 static class Entry <K,V> extends HashMap .Node<K,V> { Entry<K,V> before, after; Entry(int hash, K key, V value, Node<K,V> next) { super (hash, key, value, next); } }
可以看到,仍使用next节点维护节点间的访问顺序,但新增了before节点和after节点维护节点间的插入顺序。
2.10.4.2 扩展属性 扩展属性源码:
java 1 2 3 4 5 6 transient LinkedHashMap.Entry<K,V> head;transient LinkedHashMap.Entry<K,V> tail;final boolean accessOrder;
通过accessOrder支持LRU算法,即最近最少使用算法,是一种元素删除方法,表示删除最近一段时间内最少使用的元素。
双向链表是按时间顺序排列的,插入的元素永远在尾部,访问的元素是否要移动到尾部是通过accessOrder判断的:
当accessOrder为true时,访问的元素会被放置到双向链表尾部,表示双向链表是按照访问顺序排列的。
当accessOrder为false时,访问的元素不会被处理,表示双向链表是按照插入顺序排列的。
2.10.4.3 扩展方法 扩展方法源码:
java 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 Node<K,V> newNode (int hash, K key, V value, Node<K,V> e) { LinkedHashMap.Entry<K,V> p = new LinkedHashMap .Entry<K,V>(hash, key, value, e); linkNodeLast(p); return p; } private void linkNodeLast (LinkedHashMap.Entry<K,V> p) { LinkedHashMap.Entry<K,V> last = tail; tail = p; if (last == null ) head = p; else { p.before = last; last.after = p; } } public V get (Object key) { Node<K,V> e; if ((e = getNode(hash(key), key)) == null ) return null ; if (accessOrder) afterNodeAccess(e); return e.value; } void afterNodeAccess (Node<K,V> e) { LinkedHashMap.Entry<K,V> last; if (accessOrder && (last = tail) != e) { LinkedHashMap.Entry<K,V> p = (LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after; p.after = null ; if (b == null ) head = a; else b.after = a; if (a != null ) a.before = b; else last = b; if (last == null ) head = p; else { p.before = last; last.after = p; } tail = p; ++modCount; } } void afterNodeInsertion (boolean evict) { LinkedHashMap.Entry<K,V> first; if (evict && (first = head) != null && removeEldestEntry(first)) { K key = first.key; removeNode(hash(key), key, null , false , true ); } } void afterNodeRemoval (Node<K,V> e) { LinkedHashMap.Entry<K,V> p = (LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after; p.before = p.after = null ; if (b == null ) head = a; else b.after = a; if (a == null ) tail = b; else a.before = b; }
2.10.4.4 构造方法 构造方法源码:
java 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public LinkedHashMap (int initialCapacity, float loadFactor) { super (initialCapacity, loadFactor); accessOrder = false ; } public LinkedHashMap (int initialCapacity) { super (initialCapacity); accessOrder = false ; } public LinkedHashMap () { super (); accessOrder = false ; } public LinkedHashMap (Map<? extends K, ? extends V> m) { super (); accessOrder = false ; putMapEntries(m, false ); } public LinkedHashMap (int initialCapacity, float loadFactor, boolean accessOrder) { super (initialCapacity, loadFactor); this .accessOrder = accessOrder; }
2.10.4.5 常用方法 常用方法同HashMap。
2.11 TreeMap 2.11.1 简介 不允许插入key值相同的元素,定制排序允许插入null的key值,自然排序不允许插入null的key值。
底层是红黑树,支持自然排序和定制排序。自然排序要求key值实现Comparable接口,定制排序要求创建TreeMap时传入Comparator元素。
线程不安全。
2.11.2 方法 构造方法:
java 1 2 3 4 5 6 7 8 public TreeMap () ;public TreeMap (Comparator<? super K> comparator) ;public TreeMap (Map<? extends K, ? extends V> m) ;public TreeMap (SortedMap<K, ? extends V> m) ;
常用方法:
java 1 2 3 4 5 6 public V get (Object key) ;public V put (K key, V value) ;public V remove (Object key) ;
2.11.3 源码 2.11.3.1 属性 属性源码:
java 1 2 3 4 5 6 7 8 private final Comparator<? super K> comparator;private transient Entry<K,V> root;private transient int size = 0 ;private transient int modCount = 0 ;
2.11.3.2 构造方法 构造方法源码:
java 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public TreeMap () { comparator = null ; } public TreeMap (Comparator<? super K> comparator) { this .comparator = comparator; } public TreeMap (Map<? extends K, ? extends V> m) { comparator = null ; putAll(m); } public TreeMap (SortedMap<K, ? extends V> m) { comparator = m.comparator(); try { buildFromSorted(m.size(), m.entrySet().iterator(), null , null ); } catch (java.io.IOException cannotHappen) { } catch (ClassNotFoundException cannotHappen) { } }
2.11.3.3 常用方法 常用方法源码:
java 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 public V get (Object key) { Entry<K,V> p = getEntry(key); return (p == null ? null : p.value); } final Entry<K,V> getEntry (Object key) { if (comparator != null ) return getEntryUsingComparator(key); if (key == null ) throw new NullPointerException (); Comparable<? super K> k = (Comparable<? super K>) key; Entry<K,V> p = root; while (p != null ) { int cmp = k.compareTo(p.key); if (cmp < 0 ) p = p.left; else if (cmp > 0 ) p = p.right; else return p; } return null ; } final Entry<K,V> getEntryUsingComparator (Object key) { K k = (K) key; Comparator<? super K> cpr = comparator; if (cpr != null ) { Entry<K,V> p = root; while (p != null ) { int cmp = cpr.compare(k, p.key); if (cmp < 0 ) p = p.left; else if (cmp > 0 ) p = p.right; else return p; } } return null ; } public V put (K key, V value) { Entry<K,V> t = root; if (t == null ) { compare(key, key); root = new Entry <>(key, value, null ); size = 1 ; modCount++; return null ; } int cmp; Entry<K,V> parent; Comparator<? super K> cpr = comparator; if (cpr != null ) { do { parent = t; cmp = cpr.compare(key, t.key); if (cmp < 0 ) t = t.left; else if (cmp > 0 ) t = t.right; else return t.setValue(value); } while (t != null ); } else { if (key == null ) throw new NullPointerException (); Comparable<? super K> k = (Comparable<? super K>) key; do { parent = t; cmp = k.compareTo(t.key); if (cmp < 0 ) t = t.left; else if (cmp > 0 ) t = t.right; else return t.setValue(value); } while (t != null ); } Entry<K,V> e = new Entry <>(key, value, parent); if (cmp < 0 ) parent.left = e; else parent.right = e; fixAfterInsertion(e); size++; modCount++; return null ; } public V remove (Object key) { Entry<K,V> p = getEntry(key); if (p == null ) return null ; V oldValue = p.value; deleteEntry(p); return oldValue; }
3 工具类 3.1 Arrays 3.1.1 简介 Arrays工具类主要用来操作数组。
3.1.2 方法 3.1.2.1 打印 打印数组。
示例:
java 1 2 3 4 5 6 7 8 9 10 public static void main (String[] args) { Integer[] ints = new Integer [5 ]; ints[0 ] = 1 ; ints[1 ] = 6 ; ints[2 ] = 4 ; ints[3 ] = 9 ; ints[4 ] = 3 ; System.out.println(ints); System.out.println(Arrays.toString(ints)); }
3.1.2.2 排序 将数组里的元素进行排序。
示例:
java 1 2 3 4 5 6 7 8 9 10 11 public static void main (String[] args) { Integer[] ints = new Integer [5 ]; ints[0 ] = 1 ; ints[1 ] = 6 ; ints[2 ] = 4 ; ints[3 ] = 9 ; ints[4 ] = 3 ; System.out.println(Arrays.toString(ints)); Arrays.sort(ints); System.out.println(Arrays.toString(ints)); }
3.1.2.3 比较 判断两个数组是否相等。
示例:
java 1 2 3 4 5 6 7 8 9 public static void main (String[] args) { Integer[] ints1 = new Integer [2 ]; ints1[0 ] = 1 ; ints1[1 ] = 6 ; Integer[] ints2 = new Integer [2 ]; ints2[0 ] = 4 ; ints2[1 ] = 3 ; System.out.println(Arrays.equals(ints1, ints2)); }
3.1.2.4 复制 复制数组。
示例:
java 1 2 3 4 5 6 7 8 9 10 public static void main (String[] args) { Integer[] ints1 = new Integer [5 ]; ints1[0 ] = 1 ; ints1[1 ] = 6 ; ints1[2 ] = 4 ; ints1[3 ] = 9 ; ints1[4 ] = 3 ; Integer[] ints2 = Arrays.copyOf(ints1, 3 ); System.out.println(Arrays.toString(ints2)); }
3.1.2.5 数组转集合 将数组转为集合。
示例:
java 1 2 3 4 5 6 7 8 9 10 public static void main (String[] args) { Integer[] ints = new Integer [5 ]; ints[0 ] = 1 ; ints[1 ] = 6 ; ints[2 ] = 4 ; ints[3 ] = 9 ; ints[4 ] = 3 ; List<Integer> list = Arrays.asList(ints); System.out.println(list); }
3.2 Collections 3.2.1 简介 Collections工具类主要用来操作集合类,比如List和Set。
3.2.2 方法 3.2.2.1 排序 使用Collections工具类里的sort()方法进行排序,必须满足下列任意一个条件:
第一种是List中的存储的元素实现Comparable接口,重写compareTo()方法。
第二种是在使用sort方法时,传入一个Comparator的实现类,重写compareTo()方法。
示例:
java 1 2 3 4 5 6 7 8 List<Integer> list = new ArrayList <Integer>(); list.add(3 ); list.add(5 ); list.add(1 ); System.out.println(list); Collections.sort(list); System.out.println(list);
3.2.2.2 反转 将集合里元素的顺序进行反转。
示例:
java 1 2 3 4 5 6 7 List<Integer> list = new ArrayList <Integer>(); list.add(3 ); list.add(5 ); list.add(1 ); System.out.println(list); Collections.reverse(list); System.out.println(list);
3.2.2.3 混排 对集合里的元素进行随机排序。
示例:
java 1 2 3 4 5 6 7 List<Integer> list = new ArrayList <Integer>(); list.add(3 ); list.add(5 ); list.add(1 ); System.out.println(list); Collections.shuffle(list); System.out.println(list);
3.2.2.4 最大 查找集合中最大的一个元素。
示例:
java 1 2 3 4 5 6 List<Integer> list = new ArrayList <Integer>(); list.add(3 ); list.add(5 ); list.add(1 ); Integer max = Collections.max(list);System.out.println(max);
3.2.2.5 最小 查找集合中最小的一个元素。
示例:
java 1 2 3 4 5 6 List<Integer> list = new ArrayList <Integer>(); list.add(3 ); list.add(5 ); list.add(1 ); Integer min = Collections.min(list);System.out.println(min);
3.2.3 获取线程安全的容器 创建线程安全的List:
java 1 List<Integer> list = Collections.synchronizedList(new ArrayList <Integer>());
创建线程安全的Set:
java 1 Set<Integer> set = Collections.synchronizedSet(new HashSet <Integer>());
创建线程安全的Map:
java 1 Map<String, Integer> map = Collections.synchronizedMap(new HashMap <String, Integer>());
4 遍历 4.1 遍历Collection 对List和Set的遍历,有四种方式,下面以ArrayList为例进行说明。
4.1.1 普通for循环 使用普通for循环的遍历方式效率最高,尽量将循环无关的代码放置在集合外执行。
示例:
java 1 2 3 for (int i = 0 ; i < list.size(); i++) { System.out.println(i); }
如果要在普通for循环里对集合元素进行删除操作,可能会出现问题:
java 1 2 3 4 5 6 7 8 9 10 11 12 13 14 public static void main (String[] args) { List<Integer> list = new ArrayList <Integer>(); list.add(1 ); list.add(2 ); list.add(2 ); list.add(4 ); list.add(5 ); for (int i = 0 ; i < list.size(); i++) { if (list.get(i) == 2 ) { list.remove(i); } } System.out.println(list); }
集合中有两个值为2的元素,但是在代码执行之后,值为2的元素并没有完全移除。
在第一次删除后,集合发生了改变,删除位置之后的所有元素都向前挪动了一个位置,删除位置的元素由下一位置的元素替代。
在下次遍历时,从删除位置后开始判断,跳过了删除位置的元素,从而导致最后打印的结果和预期的不一致。
改进的办法是在删除之后设置索引减1,重新判断删除位置的元素。
4.1.2 增强for循环 进一步精简了遍历的代码,底层使用迭代器。
示例:
java 1 2 3 for (Integer i : list) { System.out.println(i); }
如果在增强for循环里删除或者添加集合元素,那么一定会报异常:
java 1 2 3 4 5 6 7 8 9 10 11 12 13 14 public static void main (String[] args) { List<Integer> list = new ArrayList <Integer>(); list.add(1 ); list.add(2 ); list.add(2 ); list.add(4 ); list.add(5 ); for (Integer i : list) { if (i == 2 ) { list.remove(i); } } System.out.println(list); }
运行后会抛出java.util.ConcurrentModificationException异常。
抛出异常是由快速失败(fail-fast)机制引起的,该机制是为了避免在遍历集合时,对集合的结构进行修改。
快速失败机制使用modCount记录集合的修改次数,在删除时除了删除对应元素外,还会更新modCount。
增强for循环使用迭代器进行遍历,迭代器在初始化时会使用expectedModCount记录当时的modCount,遍历时会检查expectedModCount是否和modCount相同,如果不同就会抛出异常。
4.1.3 使用迭代器 示例:
java 1 2 3 4 Iterator<Integer> iterator = list.iterator(); while (iterator.hasNext()) { System.out.println(iterator.next()); }
如果在迭代器中使用集合提供的删除或添加方法,同样会报错:
java 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public static void main (String[] args) { List<Integer> list = new ArrayList <Integer>(); list.add(1 ); list.add(2 ); list.add(2 ); list.add(4 ); list.add(5 ); Iterator<Integer> iterator = list.iterator(); while (iterator.hasNext()) { if (iterator.next() == 2 ) { list.add(6 ); } } System.out.println(list); }
运行后会抛出java.util.ConcurrentModificationException异常。
这里抛出异常的原因和增强for循环一样,同样是因为快速失败机制。
解决办法是在迭代器中删除或添加元素时,使用迭代器提供的删除或添加方法,不要使用集合提供的删除或添加方法。
需要注意的是,普通迭代器中只提供了删除方法,在集合迭代器中还提供了添加和修改方法。
4.1.4 使用集合迭代器 示例:
java 1 2 3 4 ListIterator<Integer> iterator = list.listIterator(); while (iterator.hasNext()) { System.out.println(iterator.next()); }
在迭代器中使用迭代器提供的删除或添加方法:
java 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public static void main (String[] args) { List<Integer> list = new ArrayList <Integer>(); list.add(1 ); list.add(2 ); list.add(2 ); list.add(4 ); list.add(5 ); ListIterator<Integer> iterator = list.listIterator(); while (iterator.hasNext()) { if (iterator.next() == 2 ) { iterator.remove(); } } System.out.println(list); }
迭代器提供的方法同时维护了modCount和expectedModCount,所以不会产生快速失败。
4.1.5 使用forEach方法 forEach方法是JDK1.8新增的方法,需要配合Lambda表达式使用。
示例:
java 1 list.forEach(i -> System.out.println(i));
使用forEach方法遍历:
java 1 2 3 4 5 6 7 8 9 10 11 12 13 14 public static void main (String[] args) { List<Integer> list = new ArrayList <Integer>(); list.add(1 ); list.add(2 ); list.add(2 ); list.add(4 ); list.add(5 ); list.forEach(i -> { if (i == 2 ) { list.remove(i); } }); System.out.println(list); }
运行后会抛出java.util.ConcurrentModificationException异常。
这里抛出异常的原因也是因为快速失败机制。
4.2 遍历Map 对Map的遍历,有四种方式,下面以HashMap为例进行说明。
4.2.1 通过keySet()方法遍历key和value 通过keySet()方法获取到map的所有key值,遍历key值的集合,获取对应的value值。
示例:
java 1 2 3 for (Integer i : map.keySet()) { System.out.println(i + " >>> " + map.get(i)); }
结果:
log 1 2 3 4 5 0 >>> 000 1 >>> 111 2 >>> 222 3 >>> 333 4 >>> 444
在遍历的时候是可以修改的,但是不能添加和删除,否则会抛出ConcurrentModificationException异常。
示例:
java 1 2 3 4 5 6 for (Integer i : map.keySet()) { System.out.println(i + " >>> " + map.get(i)); if (map.get(i) == "222" ) { map.put(i, "999" ); } }
结果:
log 1 2 3 4 5 0 >>> 000 1 >>> 111 2 >>> 999 3 >>> 333 4 >>> 444
4.2.2 通过entrySet()方法遍历key和value 这种方式同样支持修改,但不支持添加和删除,这种方式的效率最高。
示例:
java 1 2 3 for (Map.Entry<Integer, String> entry : map.entrySet()) { System.out.println(entry.getKey() + " >>> " + entry.getValue()); }
4.2.3 通过entrySet()方法获取迭代器遍历key和value 这种方式同样支持修改,但不支持添加和删除。
示例:
java 1 2 3 4 5 Iterator<Map.Entry<Integer, String>> iterator = map.entrySet().iterator(); while (iterator.hasNext()) { Map.Entry<Integer, String> entry = iterator.next(); System.out.println(entry.getKey() + " >>> " + entry.getValue()); }
4.2.4 通过values()方法遍历所有的value 这种方式只能遍历value,不能遍历key。
示例:
java 1 2 3 for (String value : map.values()) { System.out.println(value); }
5 失败机制 5.1 快速失败机制 快速失败机制,即fail-fast机制,直接在容器上进行遍历,在遍历过程中一旦发现集合的结构发生改变,就会抛出ConcurrentModificationException异常导致遍历失败。
在java.util包下的集合类都是快速失败机制的,常见的的使用fail-fast方式遍历的容器有ArrayList和HashMap等。
fail-fast机制不能保证在不同步的修改下一定会抛出异常,它只是尽最大努力抛出,因此这种机制一般用于检测BUG。
5.1.1 复现 触发fail-fast机制的案例:
java 1 2 3 4 5 6 7 8 9 10 11 public static void main (String[] args) { List<String> list = new ArrayList <>(); list.add("00" ); list.add("11" ); list.add("22" ); for (String s : list) { if ("00" .equals(s)) { list.add("99" ); } } }
此处只是列举了一个普通案例,实际上在List、Set、Map中都会发生,并且在单线程和多线程环境下都会发生。
5.1.2 原因 fail-fast机制在单线程和多线程环境中均可发生,倘若在迭代遍历过程中检测到集合结构有变化,就有可能触发并抛出异常。
想要理解fail-fast机制,就需要查看底层源码的逻辑,因为引发fail-fast机制的原理是一样的,本文以ArrayList为例进行分析。
查看ArrayList的迭代器方法:
java 1 2 3 public Iterator<E> iterator () { return new Itr (); }
继续查看ArrayList维护的内部类Itr,需要重点关注三个属性:
java 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 private class Itr implements Iterator <E> { int cursor; int lastRet = -1 ; int expectedModCount = modCount; public boolean hasNext () { return cursor != size; } @SuppressWarnings("unchecked") public E next () { checkForComodification(); int i = cursor; if (i >= size) throw new NoSuchElementException (); Object[] elementData = ArrayList.this .elementData; if (i >= elementData.length) throw new ConcurrentModificationException (); cursor = i + 1 ; return (E) elementData[lastRet = i]; } ... final void checkForComodification () { if (modCount != expectedModCount) throw new ConcurrentModificationException (); } }
通过分析迭代器源码可以发现,迭代器的checkForComodification方法是判断是否要触发fail-fast机制的关键。
在checkForComodification方法中可以看到,是否要抛出异常在于modCount是否发生改变。
查看ArrayList源码,发现modCount的改变发生在对集合修改中,比如add操作。
所以当在使用迭代器遍历集合时,如果同时对集合进行了修改,导致modCount发生改变,就会触发fail-fast机制,抛出异常。
5.1.3 解决 有两种解决方式:
使用迭代器提供的方法:为了避免触发fail-fast机制,在迭代集合时,需要使用迭代器提供的修改方法修改集合。
使用线程安全的集合类:也可以使用线程安全的集合类,使用CopyOnWriteArrayList代替ArrayList,使用ConcerrentHashMap代替HashMap。
5.2 安全失败机制 安全失败机制,即fail-safe机制,在集合的克隆元素上进行遍历,对集合的修改不会影响遍历操作。
在java.util.concurrent包下的集合类都是安全失败的,可以在多线程下并发使用并发修改,常见的的使用fail-safe方式遍历的容器有CopyOnWriteArrayList和ConcurrentHashMap等。
基于克隆元素的遍历避免了在修改集合时抛出ConcurrentModificationException异常,但同样导致遍历时不能访问修改后的内容。
条